Лекция 8
Передача и кодирование информации
1. Передача информации. Информационные каналы 2. Характеристики информационного канала 3. Абстрактный алфавит 4. Кодирование и декодирование 5. Понятие о теоремах Шеннона 6. Международные системы байтового кодирования 7. Кодирование информации7.2.1. Кодирование растровых изображений
7.2.2. Кодирование векторных изображений.
1. Передача информации. Информационные каналы
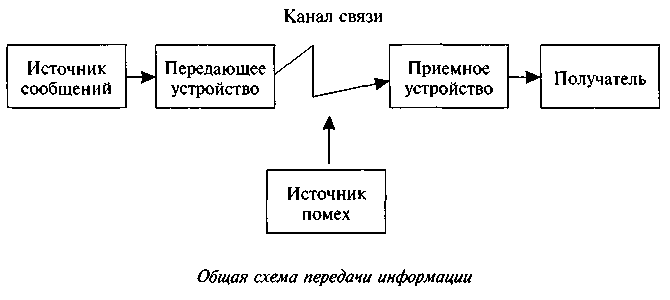
Информация передается в виде сообщений от некоторого источника информации к ее приемнику посредством канала связи между ними. Источник посылает передаваемое сообщение, которое кодируется в передаваемый сигнал. Этот сигнал посылается по каналу связи. В результате в приемнике появляется принимаемый сигнал, который декодируется и становится принимаемым сообщением. Передача информации по каналам связи часто сопровождается воздействием помех, вызывающих искажение и потерю информации.
Любое событие или явление может быть выражено по-разному, разными способами, разным алфавитом. Чтобы информацию более точно и экономно передать по каналам связи, ее надо соответственно закодировать.
Информация не может существовать без материального носителя, без передачи энергии. Закодированное сообщение приобретает вид сигналов-носителей информации, которые идут по каналу. Выйдя на приемник, сигналы должны обрести вновь общепонятный вид с помощью декодирующего устройства.
Совокупность устройств, предметов или объектов, предназначенных для передачи информации от одного из них, именуемого источником, к другому, именуемому приемником, называется каналом информации, или информационным каналом
.Примером канала может служить почта. Информация, закодированная в виде текста, помещается в конверт, поступает в почтовый ящик, извлекается оттуда и перевозится в почтовое отделение, где сортируется (вручную или машиной). Далее информация перемещается с помощью поезда (самолета, теплохода и т.п.) в почтовое отделение пункта назначения, сортируется и доставляется адресату. Таким образом, почтовый канал включает в себя: конверт (предмет), транспорт и сортировочные машины (устройства), почтовых работников (объекты). Информация, помещенная в этот канал, остается неизменной
.Другим примером может служить телефон. При телефонной передаче источник сообщения – говорящий. Кодирующее устройство, изменяющее звуки слов в электрические импульсы, – микрофон. Канал, по которому передается информация, – телефонный провод. Часть трубки, которую мы подносим к уху, выполняет роль декодирующего устройства (электрические сигналы снова преобразуются в звуки). Информация поступает в “принимающее устройство” – ухо человека на другом конце провода. Канал включает в себя телефонные аппараты (устройства), провода (предметы) и аппаратуру АТС (устройства). Особенностью этого информационного канала является то обстоятельство, что при поступлении в него информация, представленная в виде звуковых волн, преобразуется в электрические колебания и затем передается. Такой канал называется каналом с преобразованием информации
.Еще один пример – компьютер. Отдельные его системы передают одна другой информацию с помощью сигналов. Компьютер – устройство для обработки информации (как станок – устройство для обработки металла), он не создает из “ничего” информацию, а преобразует то, что в него введено. Компьютер является информационным каналом с преобразованием информации: информация поступает с внешних устройств (клавиатура, диск, микрофон), преобразуется во внутренний код и обрабатывается, преобразуется в вид, пригодный для восприятия внешним выходным устройством (монитором,
печатающим устройством, динамиками и др.), и передается на них.Живой нерв канал связи совершенно другой природы. Здесь все сообщения передаются нервным импульсом. Но в технических каналах связи направление передачи информации может меняться, а по нервной системе передача идет в одном направлении.
2. Характеристики информационного канала
Информационные каналы различаются по своей пропускной способности.
Пропускная способность
– это количество информации, передаваемое каналом в единицу времени. Измеряется пропускная способность в бит/с. В честь изобретателя телеграфа этой единице было дано имя Бод:1 Бод = 1 бит/с.
Пропускная способность информационного канала определяется двумя параметрами: разрядностью и частотой. Она пропорциональна их произведению.
Разрядностью называют максимальное количество информации, которое может быть одновременно помещено в канал.
Частота показывает, сколько раз информация может быть помещена в канал в течение единицы времени.
Разрядность почтового канала огромна. Так, пересылая по почте, например, лазерный диск, можно поместить одновременно в канал более 600 Мб информации. В то же время частота почтового канала очень низкая – выемка почты из ящиков происходит не чаще пяти раз в сутки.
Телефонный канал информации однобитный: одновременно по телефонному проводу можно послать или единицу (ток, импульс), или ноль. Частота этого канала может достигать десятки и сотни тысяч циклов в секунду. Это свойство телефонной сети позволяет использовать ее для связи между компьютерами.
Информация передается в виде сообщений. Дискретная информация записывается с помощью некоторого конечного набора знаков, которые будем называть буквами, не вкладывая в это слово привычного ограниченного значения (типа “русские буквы” или “латинские буквы”). Буква в данном расширенном понимании – любой из знаков, которые некоторым соглашением установлены для общения. Например, при привычной передаче сообщений на русском языке такими знаками будут русские буквы – прописные и строчные, знаки препинания, пробел; если в тексте есть числа – то и цифры. Вообще, буквой будем называть элемент некоторого конечного множества (набора) отличных друг от друга знаков. Множество знаков, в котором определен их порядок, назовем алфавитом (общеизвестен порядок знаков в русском алфавите: А, Б,..., Я).
Рассмотрим некоторые примеры алфавитов.
1, Алфавит прописных русских букв:
А Б В Г Д Е Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я
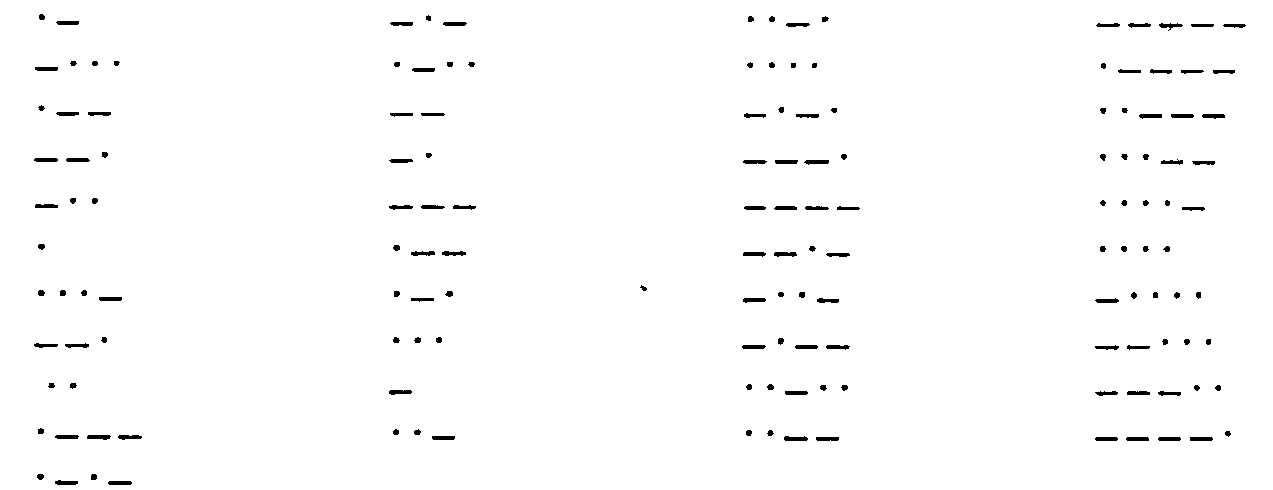
2. Алфавит Морзе:
3. Алфавит клавиатурных символов ПЭВМ
IBM (русифицированная клавиатура):
4. Алфавит знаков правильной шестигранной игральной кости:

5. Алфавит арабских цифр:
0123456789
6. Алфавит шестнадцатиричных цифр:
0 1 2 3 4 5 6 7 8 9 A B C D E F
Этот пример, в частности, показывает, что знаки одного алфавита могут образовываться из знаков других алфавитов.
7. Алфавит двоичных цифр:
0 1
Алфавит 7 является одним из примеров, так называемых, “двоичных” алфавитов, т.е. алфавитов, состоящих из двух знаков. Другими примерами являются двоичные алфавиты 8 и 9:
8. Двоичный алфавит “точка, “тире”:. _
9. Двоичный алфавит “плюс”, “минус”: + -
10. Алфавит прописных латинских букв:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
11. Алфавит римской системы счисления:
I V Х L С D М
12. Алфавит языка блок-схем изображения алгоритмов:
![]()
4. Кодирование и декодирование
В канале связи сообщение, составленное из символов (букв) одного алфавита, может преобразовываться в сообщение из символов (букв) другого алфавита. Правило, описывающее однозначное соответствие букв алфавитов при таком преобразовании, называют кодом. Саму процедуру преобразования сообщения называют перекодировкой. Подобное преобразование сообщения может осуществляться в момент поступления сообщения от источника в канал связи (кодирование) и в момент приема сообщения получателем (декодирование). Устройства, обеспечивающие кодирование и декодирование, будем называть соответственно кодировщиком и декодировщиком. На рис. 3 приведена схема, иллюстрирующая процесс передачи сообщения в случае перекодировки, а также воздействия помех (см. следующий пункт).
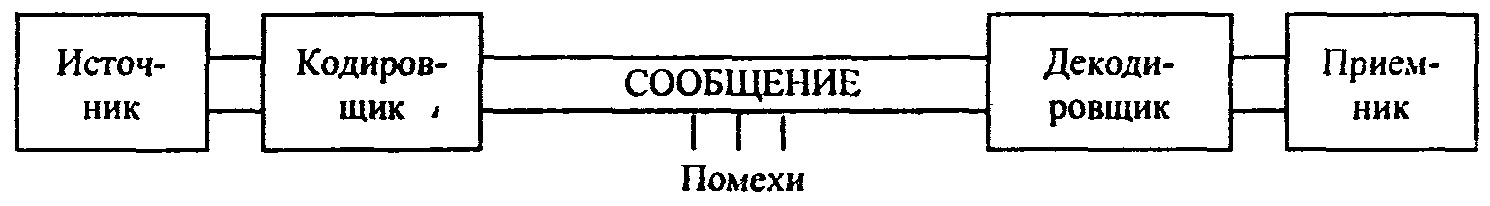
Рис. 3. Процесс передачи сообщения от источника к приемнику
Рассмотрим некоторые примеры кодов.
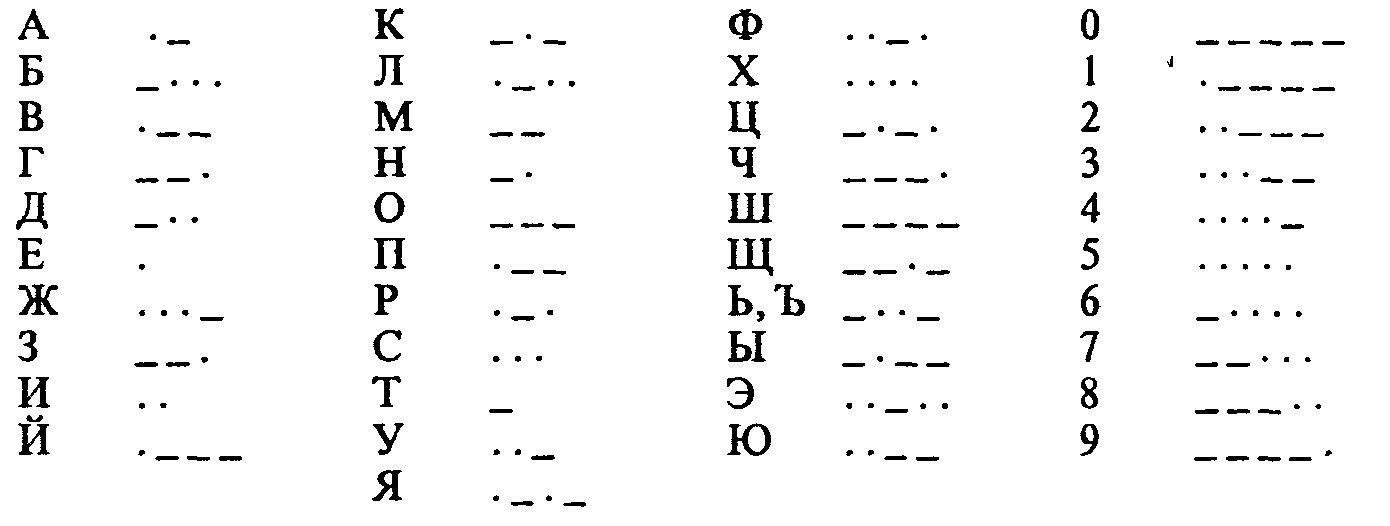
1. Азбука Морзе в русском варианте (алфавиту, составленному из алфавита русских заглавных букв и алфавита арабских цифр ставится в соответствие алфавит Морзе):
2. Код Трисиме (знакам латинского алфавита ставятся в соответствие комбинации из трех знаков: 1,2,3):
|
А |
111 |
H |
132 |
O |
223 |
V |
321 |
|
В |
112 |
I |
133 |
P |
231 |
W |
322 |
|
С |
113 |
J |
211 |
Q |
232 |
X |
323 |
|
В |
121 |
K |
212 |
R |
233 |
Y |
331 |
|
D |
122 |
L |
213 |
S |
311 |
Z |
332 |
|
F |
123 |
M |
221 |
T |
312 |
. |
333 |
|
G |
131 |
N |
222 |
U |
313 |
Код Трисиме является примером, так называемого, равномерного кода (такого, в котором все кодовые комбинации содержат одинаковое число знаков – в данном случае три). Пример неравномерного кода – азбука Морзе.
3.
Кодирование чисел знаками различных систем счисления см. лекцию 3.Теоремы Шеннона затрагивают проблему эффективного кодирования Первая теорема декларирует возможность создания системы эффективного кодирования дискретных сообщений, у которой среднее число двоичных символов на один символ сообщения асимптотически стремится к энтропии источника сообщений (в отсутствии помех). Вторая теорема Шеннона гласит, что при наличии помех в канале всегда можно найти такую систему кодирования, при которой сообщения будут переданы с заданной достоверностью.
6. Международные системы байтового кодирования
Информатика и ее приложения интернациональны. Это связано как с объективными потребностями человечества в единых правилах и законах хранения, передачи и обработки информации, так и с тем, что в этой сфере деятельности (особенно в ее прикладной части) заметен приоритет одной страны, которая благодаря этому получает возможность “диктовать моду”.
Компьютер считают универсальным преобразователем информации. Тексты на естественных языках и числа, математические и специальные символы – одним словом все, что в быту или в профессиональной деятельности может быть необходимо человеку, должно иметь возможность быть введенным в компьютер.
В силу безусловного приоритета двоичной системы счисления при внутреннем представлении информации в компьютере кодирование “внешних” символов основывается на сопоставлении каждому из них определенной группы двоичных знаков. При этом из технических соображений и из соображений удобства кодирования-декодирования следует пользоваться равномерными кодами, т.е. двоичными группами равной длины.
Попробуем подсчитать наиболее короткую длину такой комбинации с точки зрения человека, заинтересованного в использовании лишь одного естественного алфавита – скажем, английского: 26 букв следует умножить на 2 (прописные и строчные) – итого 52; 10 цифр, будем считать, 10 знаков препинания; 10 разделительных знаков (три вида скобок, пробел и др.), знаки привычных математических действий, несколько специальных символов (типа #, $, & и др.) – итого ~ 100. Точный подсчет здесь не нужен, поскольку нам предстоит решить простейшую задачу: имея, скажем, равномерный код из групп по N двоичных знаков, сколько можно образовать разных кодовых комбинаций. Ответ очевиден К = 2N. Итак, при N = 6 К = 64 – явно мало, при N = 7 К = 128 – вполне достаточно.
Однако, для кодирования нескольких (хотя бы двух) естественных алфавитов (плюс все отмеченные выше знаки) и этого недостаточно. Минимально достаточное значение N в этом случае 8; имея 256 комбинаций двоичных символов, вполне можно решить указанную задачу. Поскольку 8 двоичных символов составляют 1 байт, то говорят о системах “байтового” кодирования.
Наиболее распространены две такие системы: EBCDIC (Extended Binary Coded Decimal Interchange Code) и ASCII (American Standard Information Interchange).
Первая – исторически тяготеет к “большим” машинам, вторая чаще используется на мини- и микро-ЭВМ (включая персональные компьютеры). Ознакомимся подробнее именно с
ASCII, созданной в 1963 г.В своей первоначальной версии это – система семибитного кодирования. Она ограничивалась одним естественным алфавитом (английским), цифрами и набором различных символов, включая “символы пишущей машинки” (привычные знаки препинания, знаки математических действий и др.) и “управляющие символы”. Примеры последних легко найти на клавиатуре компьютера: для микро-ЭВМ, например,
DEL – знак удаления символа.В следующей версии фирма
IBM перешла на расширенную 8-битную кодировку. В ней первые 128 символов совпадают с исходными и имеют коды со старшим битом равным нулю, а остальные коды отданы под буквы некоторых европейских языков, в основе которых лежит латиница, греческие буквы, математические символы (скажем, знак квадратного корня) и символы псевдографики. С помощью последних можно создавать таблицы, несложные схемы и др.Для представления букв русского языка (кириллицы) в рамках
ASCII было предложено несколько версий. Первоначально был разработан ГОСТ под названием КОИ-7, оказавшийся по ряду причин крайне неудачным; ныне он практически не используется.В табл. 2 приведена часто используемая в нашей стране модифицированная альтернативная кодировка. В левую часть входят исходные коды
ASCII; в правую часть (расширение ASCII) вставлены буквы кириллицы взамен букв, немецкого, французского алфавитов (не совпадающих по написанию с английскими), греческих букв, некоторых спецсимволов.Знакам алфавита ПЭВМ ставятся в соответствие шестнадцатиричные числа по правилу: первая – номер столбца, вторая – номер строки. Например: английская 'А' – код 41, русская 'и' – код А8.
Таблица 2. Таблица кодов
ASCII (расширенная)
Одним из достоинств этой системы кодировки русских букв является их естественное упорядочение, т.е. номера букв следуют друг за другом в том же порядке, в каком сами буквы стоят в русском алфавите. Это очень существенно при решении ряда задач обработки текстов, когда требуется выполнить или использовать лексикографическое упорядочение слов.
Из сказанного выше следует, что даже 8-битная кодировка недостаточна для кодирования всех символов, которые хотелось бы иметь в расширенном алфавите. Все препятствия могут быть сняты при переходе на 16-битную кодировку Unicode, допускающую 65536 кодовых комбинаций.
. Кодирование информации7.1. Двоичное кодирование текстовой информации
Начиная с 60-х годов, компьютеры все больше стали использовать для обработки текстовой информации и в настоящее время большая часть ПК в мире занято обработкой именно текстовой информации.
Традиционно для кодирования одного символа используется количество информации равное1 байту (1 байт = 8 битов).
Для кодирования одного символа требуется один байт информации.
Учитывая, что каждый бит принимает значение 1 или 0, получаем, что с помощью 1 байта можно закодировать 256 различных символов. (28=256)
Кодирование заключается в том, что каждому символу ставиться в соответствие уникальный двоичный код от 00000000 до 11111111 (или десятичный код от 0 до 255).
Важно, что присвоение символу конкретного кода – это вопрос соглашения, которое фиксируется кодовой таблицей (например,
ASCII).Обратите внимание!
Цифры кодируются по стандарту ASCII в двух случаях – при вводе-выводе и когда они встречаются в тексте. Если цифры участвуют в вычислениях, то осуществляется их преобразование в другой двоичных код.
Возьмем число 57. При использовании в тексте каждая цифра будет представлена своим кодом в соответствии с таблицей ASCII. В двоичной системе это – 00110101 00110111.
При использовании в вычислениях код этого числа будет получен по правилам перевода в двоичную систему и получим – 00111001.
7.2. Кодирование графической информации
Под графической информацией можно понимать рисунок, чертеж, фотографию, картинку в книге, изображения на экране телевизора или в кинозале и т. д. Для обсуждения общих принципов кодирования графической информации в качестве конкретного, достаточно общего случая графического объекта выберем изображение на экране телевизора. Это изображение состоит из некоторого количества горизонтальных линий – строк. А каждая строка в свою очередь состоит из элементарных мельчайших единиц изображения – точек, которые принято называть пикселами (picsel – PICture'S ELement – элемент картинки). Весь массив элементарных единиц изображения называют растром (лат. rastrum – грабли). Степень четкости изображения зависит от количества строк на весь экран и количества точек в строке, которые представляют разрешающую способность экрана или просто разрешение. Чем больше строк и точек, тем четче и лучше изображение. Достаточно хорошим считается разрешение 640x480, то есть 640 точек на строку и 480 строчек на экран.
Строки, из которых состоит изображение, можно просматривать сверху вниз друг за другом, как бы составив из них одну сплошную линию. После полного просмотра первой строки просматривается вторая, за ней третья, потом четвертая и т. д. до последней строки экрана. Так как каждая из строк представляет собой последовательность пикселов, то все изображение, вытянутое в линию, также можно считать линейной последовательностью элементарных точек. В рассматриваемом случае эта последовательность состоит из 640x480=307200 пикселов. Вначале рассмотрим принципы кодирования монохромного изображения, то есть изображения, состоящего из любых двух контрастных цветов – черного и белого, зеленого и белого, коричневого и белого и т. д. Для простоты обсуждения будем считать, что один из цветов – черный, а второй – белый. Тогда каждый пиксел изображения может иметь либо черный, либо белый цвет. Поставив в соответствие черному цвету двоичный код “0”, а белому – код “1” (либо наоборот), мы сможем закодировать в одном бите состояние одного пикселя монохромного изображения. А так как байт состоит из 8 бит, то на строчку, состоящую из 640 точек, потребуется 80 байтов памяти, а на все изображение – 38 400 байтов.
Однако полученное таким образом изображение будет чрезмерно контрастным. Реальное черно-белое изображение состоит не только из белого и черного цветов. В него входят множество различных промежуточных оттенков – серый, светло-серый, темно-серый и т. д. Если кроме белого и черного цветов использовать только две дополнительные градации, скажем светло-серый и темно-серый, то для того чтобы закодировать цветовое состояние одного пикселя, потребуется уже два бита. При этом кодировка может быть, например, такой: черный цвет – 002, темно-серый – 012, светло-серый – 102, белый – 112.
Общепринятым на сегодняшний день, дающим достаточно реалистичные монохромные изображения, считается кодирование состояния одного пикселя с помощью одного байта, которое позволяет передавать 256 различных оттенков серого цвета от полностью белого до полностью черного. В этом случае для передачи всего растра из 640x480 пикселов потребуется уже не 38 400, а все 307 200 байтов.
Цветное изображение может формироваться различными способами. Один из них – метод RGB (от слов Red, Green, Blue – красный, зеленый, синий), который опирается на то, что глаз человека воспринимает все цвета как сумму трех основных цветов – красного, зеленого и синего. Например, сиреневый цвет – это сумма красного и синего, желтый цвет – сумма красного и зеленого и т. д. Для получения цветного пикселя в одно и то же место экрана направляется не один, а сразу три цветных луча. Опять упрощая ситуацию, будем считать, что для кодирования каждого из цветов достаточно одного бита. Нуль в бите будет означать, что в суммарном цвете данный основной отсутствует, а единица – присутствует. Следовательно, для кодирования одного цветного пиксела потребуется 3 бита – по одному на каждый цвет. Пусть первый бит соответствует красному цвету, второй – зеленому и третий – синему. Тогда код 101(2) обозначает сиреневый цвет – красный есть, зеленого нет, синий есть, а код 110(2) – желтый цвет – красный есть, зеленый есть, синего нет. При такой схеме кодирования каждый пиксел может иметь один из восьми возможных цветов. Если же каждый из цветов кодировать с помощью одного байта, как это принято для реалистического монохромного изображения, то появится возможность передавать по 256 оттенков каждого из основных цветов. А всего в этом случае обеспечивается передача 256x256x256=16 777 216 различных цветов, что достаточно близко к реальной чувствительности человеческого глаза. Таким образом, при данной схеме кодирования цвета на изображение одного пикселя требуется 3 байта, или 24 бита, памяти. Этот способ представления цветной графики принято называть режимом True Color (true color – истинный цвет) или полноцветным режимом.
Следует упомянуть еще один часто используемый метод представления цвета, в котором вместо основного цвета используется его дополнение до белого. Если три цвета: красный, зеленый и синий вместе дают белый, то дополнением для красного, очевидно, является сочетание зеленого и синего, то есть голубой цвет. Аналогичным образом дополнением для зеленого является сочетание красного и синего, то есть пурпурный, а для синего – сочетание красного и зеленого, то есть желтый цвет. Эти три цвета – голубой, пурпурный и желтый с добавлением черного образуют основные цвета в системе кодирования, которая называется CMYK (от Cyan – голубой, Magenta – пурпурный, Yellow – желтый и blacK – черный). Этот режим также относится к полноцветным, но для передачи состояния одного пикселя в этом случае требуется 32 бита, или четыре байта, памяти, и может быть передано 4 294 967 295 различных цветов.
Полноцветные режимы требуют очень много памяти. Так, для обсуждавшегося выше растра 640x480 при использовании метода RGB требуется 921 600, а для режима CMYK – 1 228 800 байтов памяти. В целях экономии памяти разрабатываются различные режимы и графические форматы, которые немного хуже передают цвет, но требуют гораздо меньше памяти. В частности, можно упомянуть режим High Color (high color – богатый цвет), в котором для передачи цвета одного пикселя используется 16 битов и, следовательно, можно передать 65 535 цветовых оттенков, а также индексный режим, который базируется на заранее созданной таблице цветовых оттенков. Нужный цвет выбирается из этой таблицы с помощью номера – индекса, который занимает всего один байт памяти.
При записи изображения в память компьютера кроме цвета отдельных точек необходимо фиксировать много дополнительной информации – размеры рисунка, яркость точек и т. д. Конкретный способ кодирования всей требуемой при записи изображения информации образует графический формат. Форматы кодирования графической информации, основанные на передаче цвета каждого отдельного пикселя, из которого состоит изображение, относят к группе растровых или BitMap форматов (bit map – битовая карта).
7.2.1. Кодирование растровых изображений
Наиболее известными растровыми форматами являются BMP, GIF и JPEG форматы. В формате BMP (от BitMaP) задается цветность всех пикселов изображения. При этом можно выбрать монохромный режим с 256 градациями или цветной с 16 256 или 16 777 216 цветами. Этот формат требует много памяти. В формате GIF (Graphics Interchange Format – графический формат обмена) используются специальные методы сжатия кода, причем поддерживается только 256 цветов. Качество изображения немного хуже, чем в формате BMP, зато код занимает в десятки раз меньше памяти. Формат JPEG (Goint Photographic Experts Group
-Уединенная группа экспертов по фотографии) использует методы сжатия, приводящие к потерям некоторых деталей. Однако поддержка 16 777 216 цветов все-таки обеспечивает высокое качество изображения. По требованиям к памяти формат JPEG занимает промежуточное положение между форматами BMP и GIF.7.2.2. Кодирование векторных изображений.
Векторное изображение представляет собой совокупность графических примитивов (точка, отрезок, эллипс…). Каждый примитив описывается математическими формулами. Кодирование зависти от прикладной среды.
Растровая графика обладает существенным недостатком – изображение, закодированное в одном из растровых форматов, очень плохо “переносит” увеличение или уменьшение его размеров – масштабирование. Для решения задач, в которых приходится часто выполнять эту операцию, были разработаны методы так называемой векторной графики. В векторной графике, в отличие от основанной на точке – пикселе – растровой графики, базовым объектом является линия. При этом изображение формируется из описываемых
математическим, векторным способом отдельных отрезков прямых или кривых линий, а также геометрических фигур – прямоугольников, окружностей и т. д., которые могут быть из них получены. Фирма Adobe разработала специальный язык PostScript (от poster script – сценарий плакатов, объявлений, афиш), служащий для описания изображений на базе указанных методов. Этот язык является основой для нескольких векторных графических форматов. В частности, можно указать форматы PS (PostScript) и EPS, которые используются для описания как векторных, так и растровых изображений, а также разнообразных текстовых шрифтов. Изображения и тексты, записанные в этих форматах, большинством популярных программ не воспринимаются, они могут просматриваться и печататься только с помощью специализированных аппаратных и программных средств.Кроме растровой и векторной графики существует еще и фрактальная графика, в которой формирование изображений целиком основано на математических формулах, уравнениях, описывающих те или иные фигуры, поверхности, тела. При этом само изображение в памяти компьютера фактически не хранится – оно получается как результат обработки некоторых данных. Таким способом могут быть получены даже довольно реалистичные изображения природных ландшафтов.
7.3. Двоичное кодирование звука
Развитие способов кодирования звуковой информации, а также движущихся изображений – анимации и видеозаписей – происходило с запаздыванием относительно рассмотренных выше разновидностей информации. Заметим, что под анимацией понимается похожее на мультипликацию “оживление” изображений, но выполняемое с помощь средств компьютерной графики. Анимация представляет собой последовательность незначительно отличающихся друг от друга, полученных с помощью компьютера картинок, которые фиксируют близкие по времени состояния движения какого-либо объекта или группы объектов. Приемлемые способы хранения и воспроизведения с помощью компьютера звуковых и видеозаписей появились только в девяностых годах двадцатого века. Эти способы работы со звуком и видео получили
название мультимедийных технологий. Звук представляет собой достаточно сложное непрерывное колебание воздуха. Оказывается, что такие непрерывные сигналы можно с достаточной точностью представлять в виде суммы некоторого числа простейших синусоидальных колебаний. Причем каждое слагаемое, то есть каждая синусоида, может быть точно задана некоторым набором числовых параметров – амплитуды, фазы и частоты, которые можно рассматривать как код звука в некоторый момент времени. Такой подход к записи звука называется преобразованием в цифровую форму, оцифровыванием или дискретизацией, так как непрерывный звуковой сигнал заменяется дискретным (то есть состоящим из раздельных элементов) набором значений сигнала в некоторые моменты времени. Количество отсчетов сигнала в единицу времени называется частотой дискретизации. В настоящее время при записи звука в мультимедийных технологиях применяются частоты 8, 11, 22 и 44 кГц. Так, частота дискретизации 44 килогерца означает, что одна секунда непрерывного звучания заменяется набором из сорока четырех тысяч отдельных отсчетов сигнала. Чем выше частота дискретизации, тем лучше качество оцифрованного звука.Как отмечалось выше, каждый отдельный отсчет можно описать некоторой совокупностью чисел, которые затем можно представить в виде некоторого двоичного кода. Качество преобразования звука в цифровую форму определяется не только частотой дискретизации, но и количеством битов памяти, отводимых на запись кода одного отсчета. Этот параметр принято называть разрядностью преобразования. В настоящее время обычно используется разрядность 8,16 и 24 бит. На описанных выше принципах основывается формат WAV (от WAVeform-audio – волновая форма аудио) кодирования звука. Получить запись звука в этом формате можно от подключаемых к компьютеру микрофона, проигрывателя, магнитофона, телевизора и других стандартно используемых устройств работы со звуком. Однако формат WAV требует очень много памяти. Так, при записи стереофонического звука с частотой дискретизации 44 килогерца и разрядностью 16 бит –
параметрами, дающими хорошее качество звучания, – на одну минуту записи требуется около десяти миллионов байтов памяти.Кроме волнового формата WAV, для записи звука широко применяется формат с названием MIDI (Musical Instruments Digital Interface – цифровой интерфейс музыкальных инструментов). Фактически этот формат представляет собой набор инструкций, команд так называемого музыкального синтезатора – устройства, которое имитирует звучание реальных музыкальных инструментов. Команды синтезатора фактически являются указаниями на высоту ноты, длительность ее звучания, тип имитируемого музыкального инструмента и т. д. Таким образом, последовательность команд синтезатора представляет собой нечто вроде нотной записи музыкальной мелодии. Получить запись звука в формате MIDI можно только от специальных электромузыкальных инструментов, которые поддерживают интерфейс MIDI. Формат MIDI обеспечивает высокое качество звука и требует значительно меньше памяти, чем формат WAV.
Кодирование видеоинформации еще более сложная проблема, чем кодирование звуковой информации, так как нужно позаботиться не только о дискретизации непрерывных движений, но и о синхронизации изображения со звуковым сопровождением. В настоящее время для этого используется формат, которой называется AVI
(Audio-Video Interleaved – чередующееся аудио и видео). Основные мультимедийные форматы AVI и WAV очень требовательны к памяти. Поэтому на практике применяются различные способы компрессии, то есть сжатия звуковых и видео- кодов. В настоящее время стандартными стали способы сжатия, предложенные MPEG (Moving Pictures Experts Group – группа экспертов по движущимся изображениям). В частности, стандарт MPEG описывает несколько популярных в настоящее время форматов записи звука. Так, например, при записи в формате МР3 при практически том же качестве звука требуется в десять раз меньше памяти, чем при использовании формата WAV. Существуют специальные программы, которые преобразуют записи звука из формата WAV в формат МР3. Совсем недавно был разработан стандарт MPEG-4, применение которого позволяет записать полнометражный цветной фильм со звуковым сопровождением на компакт-диск обычных размеров и качества.Перед завершением обсуждения общих принципов кодирования информации хотелось бы обратить внимание на один важный момент. Возьмем какой-либо двоичный код, например 1000 1100(2). Если обратиться к приведенному выше фрагменту кодовой таблицы, то можно утверждать, что это код буквы “М”. С другой стороны, можно сказать, что этим кодом задается цвет одного из пикселов монохромного изображения. Наконец, если воспользоваться правилами перевода из двоичной системы в десятичную, то можно утверждать, что это код числа +14010 (в другой интерпретации это код числа –12010). Что же это на самом деле? Интерпретация, то есть истолкование смысла одного и того же машинного кода, может быть самой разной. Один и тот же код разными программами может рассматриваться и как число, и как текст, и как изображение, и как звук. Другими словами, как именно трактуется тот или иной машинный код, определяется обрабатывающей этот код программой.