Лекция 8
Передача и кодирование информации
1. Передача информации. Информационные каналы 2. Характеристики информационного канала 3. Абстрактный алфавит 4. Кодирование и декодирование 5. Понятие о теоремах Шеннона 6. Международные системы байтового кодирования 5. Кодирование информации7
.2.1. Кодирование растровых изображений7
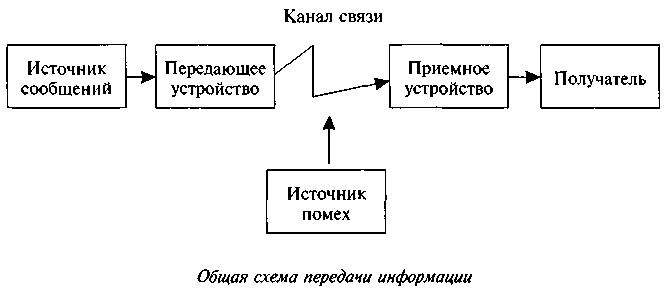
.2.2. Кодирование векторных изображений.Информация передается в виде сообщений от некоторого источника информации к ее приемнику посредством канала связи между ними. Источник посылает передаваемое сообщение, которое кодируется в передаваемый сигнал. Этот сигнал посылается по каналу связи. В результате в приемнике появляется принимаемый сигнал, который декодируется и становится принимаемым сообщением. Передача информации по каналам связи часто сопровождается воздействием помех, вызывающих искажение и потерю информации.
Любое событие или явление может быть выражено по-разному, разными способами, разным алфавитом. Чтобы информацию более точно и экономно передать по каналам связи, ее надо соответственно закодировать.
Информация не может существовать без материального носителя, без передачи энергии. Закодированное сообщение приобретает вид сигналов-носителей информации, которые идут по каналу. Выйдя на приемник, сигналы должны обрести вновь общепонятный вид с помощью декодирующего устройства.
Совокупность устройств, предметов или объектов, предназначенных для передачи информации от одного из них, именуемого источником, к другому, именуемому приемником, называется каналом информации, или информационным каналом
.Примером канала может служить почта. Информация, закодированная в виде текста, помещается в конверт, поступает в почтовый ящик, извлекается оттуда и перевозится в почтовое отделение, где сортируется (вручную или машиной). Далее информация перемещается с помощью поезда (самолета, теплохода и т.п.) в почтовое отделение пункта назначения, сортируется и доставляется адресату. Таким образом, почтовый канал включает в себя: конверт (предмет), транспорт и сортировочные машины (устройства), почтовых работников (объекты). Информация, помещенная в этот канал, остается неизменной
.Другим примером может служить телефон. При телефонной передаче источник сообщения – говорящий. Кодирующее устройство, изменяющее звуки слов в электрические импульсы, – микрофон. Канал, по которому передается информация, – телефонный провод. Часть трубки, которую мы подносим к уху, выполняет роль декодирующего устройства (электрические сигналы снова преобразуются в звуки). Информация поступает в “принимающее устройство” – ухо человека на другом конце провода. Канал включает в себя телефонные аппараты (устройства), провода (предметы) и аппаратуру АТС (устройства). Особенностью этого информационного канала является то обстоятельство, что при поступлении в него информация, представленная в виде звуковых волн, преобразуется в электрические колебания и затем передается. Такой канал называется каналом с преобразованием информации
.Еще один пример – компьютер. Отдельные его системы передают одна другой информацию с помощью сигналов. Компьютер – устройство для обработки информации (как станок – устройство для обработки металла), он не создает из “ничего” информацию, а преобразует то, что в него введено. Компьютер является информационным каналом с преобразованием информации: информация поступает с внешних устройств (клавиатура, диск, микрофон), преобразуется во внутренний код и обрабатывается, преобразуется в вид, пригодный для восприятия внешним выходным устройством (монитором, печатающим устройством, динамиками и др.), и передается на них.
Живой нерв канал связи совершенно другой природы. Здесь все сообщения передаются нервным импульсом. Но в технических каналах связи направление передачи информации может меняться, а по нервной системе передача идет в одном направлении.
. Характеристики информационного каналаИнформационные каналы различаются по своей пропускной способности.
Пропускная способность – это количество информации, передаваемое каналом в единицу времени. Измеряется пропускная способность в бит/с. В честь изобретателя телеграфа этой единице было дано имя Бод:
1 Бод = 1 бит/с.
Пропускная способность информационного канала определяется двумя параметрами: разрядностью и частотой. Она пропорциональна их произведению.
Разрядностью называют максимальное количество информации, которое может быть одновременно помещено в канал.
Частота показывает, сколько раз информация может быть помещена в канал в течение единицы времени.
Разрядность почтового канала огромна. Так, пересылая по почте, например, лазерный диск, можно поместить одновременно в канал более 600 Мб информации. В то же время частота почтового канала очень низкая – выемка почты из ящиков происходит не чаще пяти раз в сутки.
Телефонный канал информации однобитный: одновременно по телефонному проводу можно послать или единицу (ток, импульс), или ноль. Частота этого канала может достигать десятки и сотни тысяч циклов в секунду. Это свойство телефонной сети позволяет использовать ее для связи между компьютерами.
. Абстрактный алфавитИнформация передается в виде сообщений. Дискретная информация записывается с помощью некоторого конечного набора знаков, которые будем называть буквами, не вкладывая в это слово привычного ограниченного значения (типа “русские буквы” или “латинские буквы”). Буква в данном расширенном понимании – любой из знаков, которые некоторым соглашением установлены для общения. Например, при привычной передаче сообщений на русском языке такими знаками будут русские буквы – прописные и строчные, знаки препинания, пробел; если в тексте есть числа – то и цифры. Вообще, буквой будем называть элемент некоторого конечного множества (набора) отличных друг от друга знаков. Множество знаков, в котором определен их порядок, назовем алфавитом (общеизвестен порядок знаков в русском алфавите: А, Б,..., Я).
Рассмотрим некоторые примеры алфавитов.
1, Алфавит прописных русских букв:
А Б В Г Д Е Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ъ Ы Ь Э Ю Я
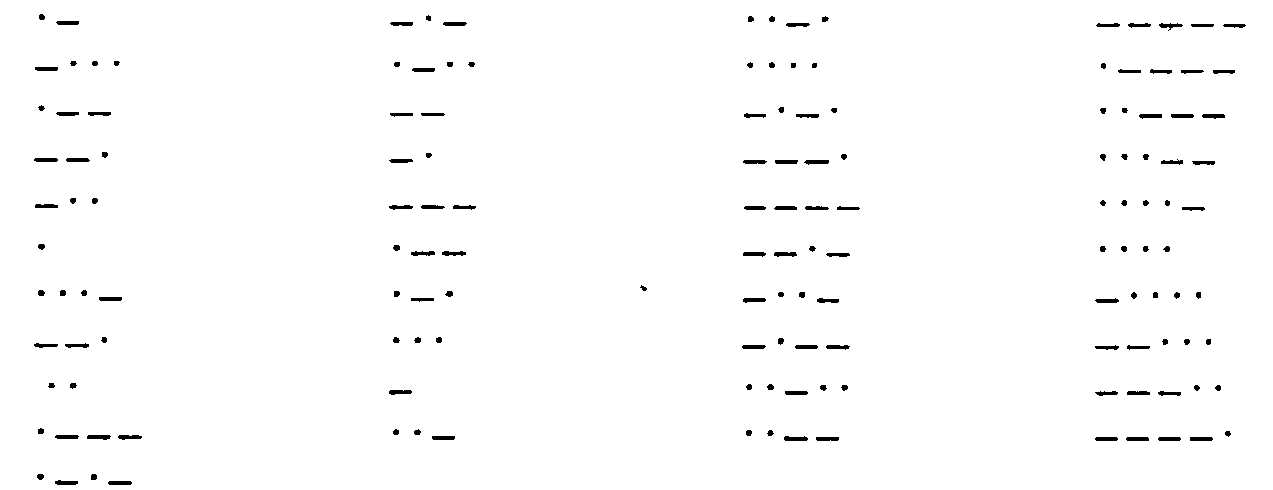
2. Алфавит Морзе:
3. Алфавит клавиатурных символов ПЭВМ
IBM (русифицированная клавиатура):
4. Алфавит знаков правильной шестигранной игральной кости:

5. Алфавит арабских цифр:
0123456789
6. Алфавит шестнадцатиричных цифр:
0 1 2 3 4 5 6 7 8 9 A B C D E F
Этот пример, в частности, показывает, что знаки одного алфавита могут образовываться из знаков других алфавитов.
7. Алфавит двоичных цифр:
0 1
Алфавит 7 является одним из примеров, так называемых, “двоичных” алфавитов, т.е. алфавитов, состоящих из двух знаков. Другими примерами являются двоичные алфавиты 8 и 9:
8. Двоичный алфавит “точка, “тире”:. _
9. Двоичный алфавит “плюс”, “минус”: + -
10. Алфавит прописных латинских букв:
A B C D E F G H I J K L M N O P Q R S T U V W X Y Z
11. Алфавит римской системы счисления:
I V Х L С D М
12. Алфавит языка блок-схем изображения алгоритмов:
![]()
В канале связи сообщение, составленное из символов (букв) одного алфавита, может преобразовываться в сообщение из символов (букв) другого алфавита. Правило, описывающее однозначное соответствие букв алфавитов при таком преобразовании, называют кодом. Саму процедуру преобразования сообщения называют перекодировкой. Подобное преобразование сообщения может осуществляться в момент поступления сообщения от источника в канал связи (кодирование) и в момент приема сообщения получателем (декодирование). Устройства, обеспечивающие кодирование и декодирование, будем называть соответственно кодировщиком и декодировщиком. На рис. 3 приведена схема, иллюстрирующая процесс передачи сообщения в случае перекодировки, а также воздействия помех (см. следующий пункт).
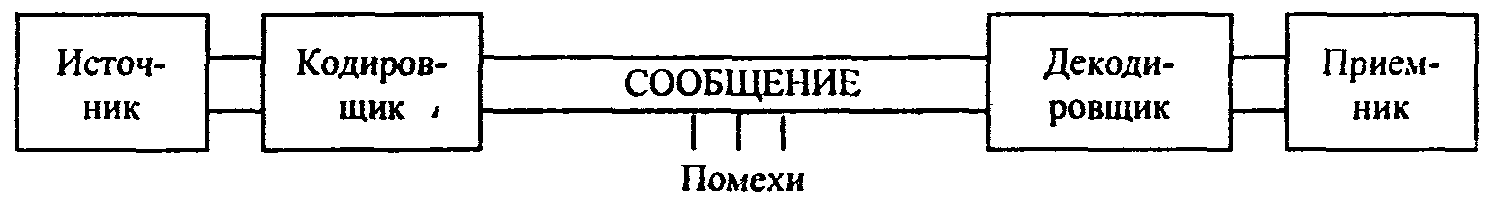
Рис. 3. Процесс передачи сообщения от источника к приемнику
Рассмотрим некоторые примеры кодов.
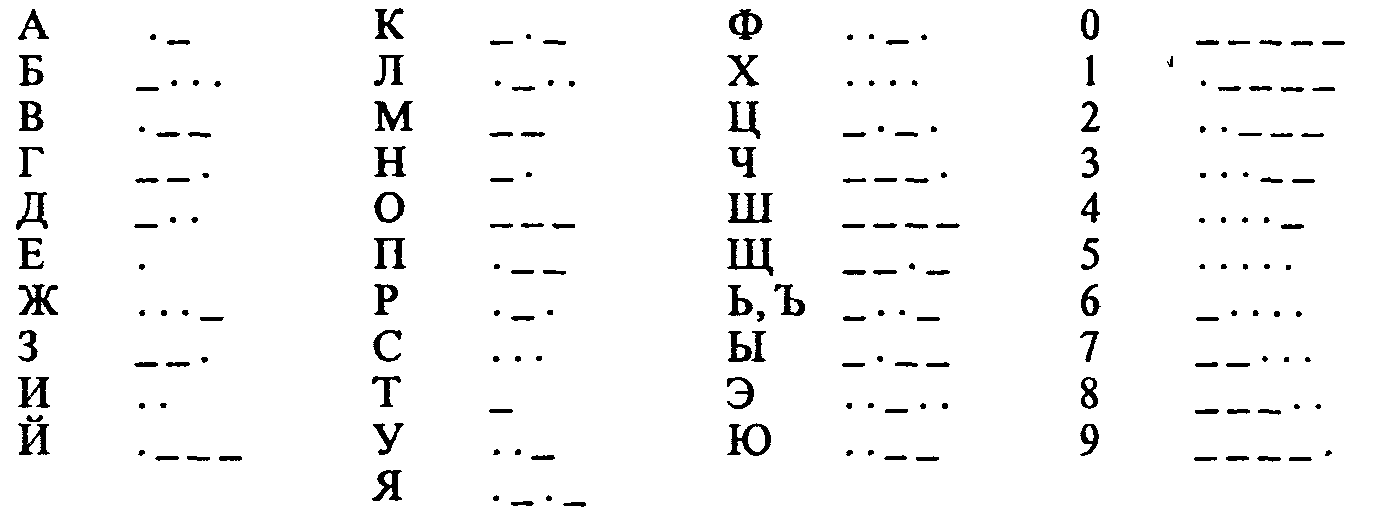
1. Азбука Морзе в русском варианте (алфавиту, составленному из алфавита русских заглавных букв и алфавита арабских цифр ставится в соответствие алфавит Морзе):
2. Код Трисиме (знакам латинского алфавита ставятся в соответствие комбинации из трех знаков: 1,2,3):
|
А |
111 |
H |
132 |
O |
223 |
V |
321 |
|
В |
112 |
I |
133 |
P |
231 |
W |
322 |
|
С |
113 |
J |
211 |
Q |
232 |
X |
323 |
|
В |
121 |
K |
212 |
R |
233 |
Y |
331 |
|
D |
122 |
L |
213 |
S |
311 |
Z |
332 |
|
F |
123 |
M |
221 |
T |
312 |
. |
333 |
|
G |
131 |
N |
222 |
U |
313 |
Код Трисиме является примером, так называемого, равномерного кода (такого, в котором все кодовые комбинации содержат одинаковое число знаков – в данном случае три). Пример неравномерного кода – азбука Морзе.
3. Кодирование чисел знаками различных систем счисления см.
лекцию 3. . Понятие о теоремах ШеннонаТеоремы Шеннона затрагивают проблему эффективного кодирования Первая теорема
декларирует возможность создания системы эффективного кодирования дискретных сообщений, у которой среднее число двоичных символов на один символ сообщения асимптотически стремится к энтропии источника сообщений (в отсутствии помех). Вторая теорема Шеннона гласит, что при наличии помех в канале всегда можно найти такую систему кодирования, при которой сообщения будут переданы с заданной достоверностью. . Международные системы байтового кодированияИнформатика и ее приложения интернациональны. Это связано как с объективными потребностями человечества в единых правилах и законах хранения, передачи и обработки информации, так и с тем, что в этой сфере деятельности (особенно в ее прикладной части) заметен приоритет одной страны, которая благодаря этому получает возможность “диктовать моду”.
Компьютер считают универсальным преобразователем информации. Тексты на естественных языках и числа, математические и специальные символы – одним словом все, что в быту или в профессиональной деятельности может быть необходимо человеку, должно иметь возможность быть введенным в компьютер.
В силу безусловного приоритета двоичной системы счисления при внутреннем представлении информации в компьютере кодирование “внешних” символов основывается на сопоставлении каждому из них определенной группы двоичных знаков. При этом из технических соображений и из соображений удобства кодирования-декодирования следует пользоваться равномерными кодами, т.е. двоичными группами равной длины.
Попробуем подсчитать наиболее короткую длину такой комбинации с точки зрения человека, заинтересованного в использовании лишь одного естественного алфавита – скажем, английского: 26 букв следует умножить на 2 (прописные и строчные) – итого 52; 10 цифр, будем считать, 10 знаков препинания; 10 разделительных знаков (три вида скобок, пробел и др.), знаки привычных математических действий, несколько специальных символов (типа #, $, & и др.) — итого ~ 100. Точный подсчет здесь не нужен, поскольку нам предстоит решить простейшую задачу: имея, скажем, равномерный код из групп по N двоичных знаков, сколько можно образовать разных кодовых комбинаций. Ответ очевиден К = 2N. Итак, при N = 6 К = 64 – явно мало, при N = 7 К = 128 – вполне достаточно.
Однако, для кодирования нескольких (хотя бы двух) естественных алфавитов (плюс все отмеченные выше знаки) и этого недостаточно. Минимально достаточное значение N в этом случае 8; имея 256 комбинаций двоичных символов, вполне можно решить указанную задачу. Поскольку 8 двоичных символов составляют 1 байт, то говорят о системах “байтового” кодирования.
Наиболее распространены две такие системы: EBCDIC (Extended Binary Coded Decimal Interchange Code) и ASCII (American Standard Information Interchange).
Первая – исторически тяготеет к “большим” машинам, вторая чаще используется на мини- и микро-ЭВМ (включая персональные компьютеры). Ознакомимся подробнее именно с
ASCII, созданной в 1963 г.В своей первоначальной версии это – система семибитного кодирования. Она ограничивалась одним естественным алфавитом (английским), цифрами и набором различных символов, включая “символы пишущей машинки” (привычные знаки препинания, знаки математических действий и др.) и “управляющие символы”. Примеры последних легко найти на клавиатуре компьютера: для микро-ЭВМ, например,
DEL – знак удаления символа.В следующей версии фирма
IBM перешла на расширенную 8-битную кодировку. В ней первые 128 символов совпадают с исходными и имеют коды со старшим битом равным нулю, а остальные коды отданы под буквы некоторых европейских языков, в основе которых лежит латиница, греческие буквы, математические символы (скажем, знак квадратного корня) и символы псевдографики. С помощью последних можно создавать таблицы, несложные схемы и др.Для представления букв русского языка (кириллицы) в рамках
ASCII было предложено несколько версий. Первоначально был разработан ГОСТ под названием КОИ-7, оказавшийся по ряду причин крайне неудачным; ныне он практически не используется.В табл. 2 приведена часто используемая в нашей стране модифицированная альтернативная кодировка. В левую часть входят исходные коды
ASCII; в правую часть (расширение ASCII) вставлены буквы кириллицы взамен букв, немецкого, французского алфавитов (не совпадающих по написанию с английскими), греческих букв, некоторых спецсимволов.Знакам алфавита ПЭВМ ставятся в соответствие шестнадцатиричные числа по правилу: первая – номер столбца, вторая – номер строки. Например: английская 'А' – код 41, русская 'и' – код А8.
Таблица 2. Таблица кодов
ASCII (расширенная)
Одним из достоинств этой системы кодировки русских букв является их естественное упорядочение, т.е. номера букв следуют друг за другом в том же порядке, в каком сами буквы стоят в русском алфавите. Это очень существенно при решении ряда задач обработки текстов, когда требуется выполнить или использовать лексикографическое упорядочение слов.
Из сказанного выше следует, что даже 8-битная кодировка недостаточна для кодирования всех символов, которые хотелось бы иметь в расширенном алфавите. Все препятствия могут быть сняты при переходе на 16-битную кодировку Unicode, допускающую 65536 кодовых комбинаций.
Кодирование информации Двоичное кодирование текстовой информацииНачиная с 60-х годов, компьютеры все больше стали использовать для обработки текстовой информации и в настоящее время большая часть ПК в мире занято обработкой именно текстовой информации.
Традиционно для кодирования одного символа используется количество информации равное1 байту (1 байт = 8 битов).
Для кодирования одного символа требуется один байт информации.
Учитывая, что каждый бит принимает значение 1 или 0, получаем, что с помощью 1 байта можно закодировать 256 различных символов. (28=256)
Кодирование заключается в том, что каждому символу ставиться в соответствие уникальный двоичный код от 00000000 до 11111111 (или десятичный код от 0 до 255).
Важно, что присвоение символу конкретного кода – это вопрос соглашения, которое фиксируется кодовой таблицей (например,
ASCII).Обратите внимание!
Цифры кодируются по стандарту ASCII в двух случаях – при вводе-выводе и когда они встречаются в тексте. Если цифры участвуют в вычислениях, то осуществляется их преобразование в другой двоичных код.
Возьмем число 57. При использовании в тексте каждая цифра будет представлена своим кодом в соответствии с таблицей ASCII. В двоичной системе это – 00110101 00110111.
При использовании в вычислениях код этого числа будет получен по правилам перевода в двоичную систему и получим – 00111001.
Кодирование графической информацииСоздавать и хранить графические объекты в компьютере можно двумя способами – как растровое или как векторное изображение. Для каждого типа изображений используется свой способ кодирования.
7.2.1. Кодирование растровых изображений
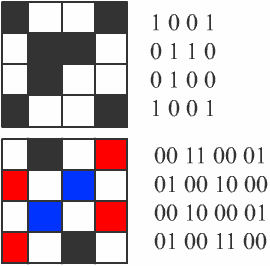
Для черно-белого изображения информационный объем одной точки равен одному биту (либо черная, либо белая – либо 1, либо 0).
Для четырех цветного – 2 бита.
Для 8 цветов необходимо – 3 бита.
Для 16 цветов – 4 бита.
Для 256 цветов – 8 бит (1 байт
).4 294 967 296 цветов (
True Color) – 32 бита (4 байта).Цветное изображение на экране монитора формируется за счет смешивания трех базовых цветов: красного, зеленого, синего. Т.н. модель
RGB.Для получения богатой палитры базовым цветам могут быть заданы различные интенсивности.
7.2.2. Кодирование векторных изображений.
Векторное изображение представляет собой совокупность графических примитивов (точка, отрезок, эллипс…). Каждый примитив описывается математическими формулами. Кодирование зависти от прикладной среды.
Двоичное кодирование звука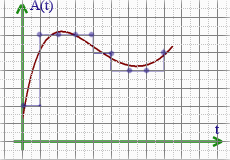
В процессе кодирования звукового сигнала производится его временная дискретизация – непрерывная волна разбивается на отдельные маленькие временные участки.
Качество двоичного кодирования звука определяется глубиной кодирования и частотой дискретизации.